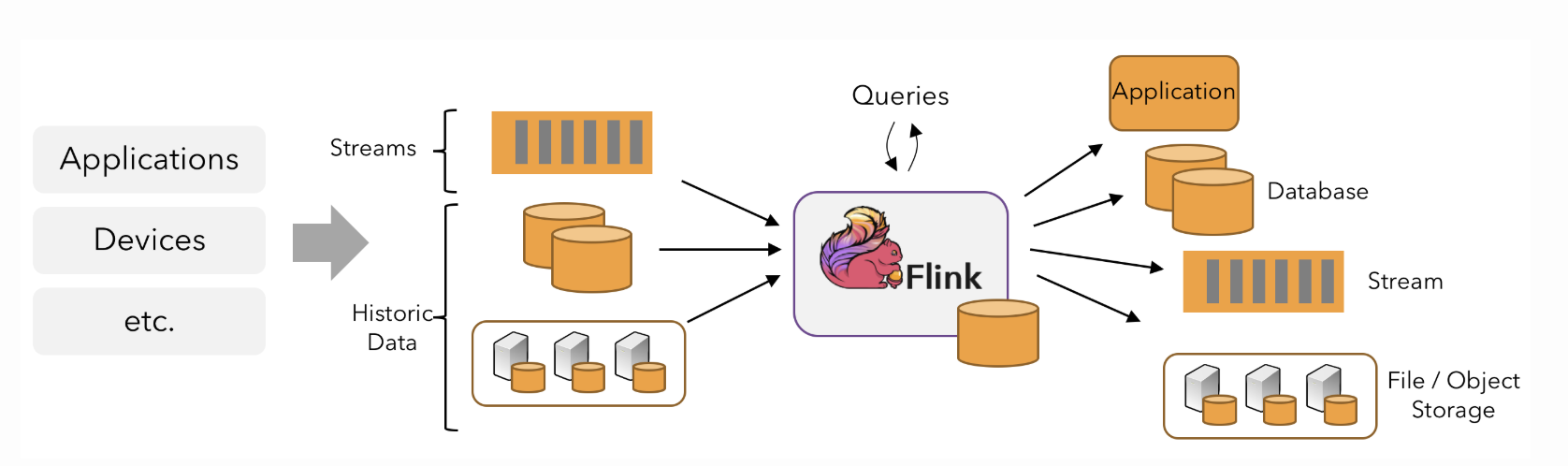
一种被设计来处理无穷数据集的数据处理系统引擎
对实时产生的数据进行实时统计分析
- 电商大促时,统计当前下单量、金额
- 实时统计 App 中的埋点数据等
流计算相比批处理需要切分为窗口才能进行分组聚合处理
同时需要解决如下两个问题
-
正确性/完整性 exactly-once
-
处理无序、延迟数据的能力
Flink对流计算提供的支持
- 同时支持高吞吐、低延迟、高性能(spark支持高吞吐和高性能,strom支持低延迟高性能)
- 支持事件时间概念
- 支持有状态的计算
- 支持高度灵活的窗口
- 基于轻量级分布式快照实现容错
- 基于JVM实现独立的内存管理
- save point(保存点)
流计算的流程

窗口
在处理无限流数据时, 如果需要对数据进行分组聚合操作,实时获取结果时, 则需要将数据分段到不同的窗口中,分别进行计算输出
窗口可分为
- 滚动窗口(时间驱动、数量驱动)
- 有固定间隔相等的连续窗口,每个窗口不会重复, 如每5分钟统计一次或每5个数据计算一次
- 滑动窗口(时间驱动、数量驱动)
- 有固定间隔相等的连续窗口,每个窗口之间可能有重叠,如每5分钟,统计前20分钟数据
- 会话窗口
- 通过数据的间隔时间(session gap)来区分窗口, 如数据间隔5分钟则开一个新的会话窗口
- 全局窗口
- 所有的数据都在一个窗口中, 此窗口需要自己出发trigger来进行计算
窗口数据计算处理
在窗口结束,触发trigger来进行计算时可以使用如下函数
- ReduceFunction 合并
- AggregateFunction 高级合并
- FoldFunction 与外部元素合并(@Deprecated,使用AggregateFunction)
- ProcessWindowFunction 对窗口中的所有元素一起进行计算(耗性能)
数据清理(可选)
对进入windowFunction前后的数据进行剔除处理
窗口使用API
1 | Keyed Windows |
时间
为了应对无序、延迟数据, 保证数据的顺序,就需要有一个用于表示数据的时间,平时用的比较多的是处理的时间
但是由于流数据可能的延迟等原因, 如果数据有前后相关性,那么使用处理时间可能就会有问题, flink把时间分类为如下三种:
- EventTime 事件发生事件
- Ingestion Time 事件进入flink的时间
- Processing Time 事件处理时间
如果使用EventTime即时间发生时间时, 除了要提供对应的方法来从数据中取出发生时间外, 还需要提供一个获取WaterMark水印的功能, 水印也是一个时间戳, 用于表示在此时间之前的数据已经全部到齐
同时, 时间窗口的计算触发也是通过判断水印时间是否大于窗口结束时间, 所以这时我们就可以使用 watermark 来让窗口延迟计算时间, 容忍迟到的数据
如果我们不想延迟窗口的计算, 又想容忍延迟的数据, 则可以使用如下方法
1 | OutputTag<String> outputTag = new OutputTag<String>("late-date"); |
状态
对于处理过程中的状态数据, 分为了 Keyed State(和key有关) 与 Operator State(和key无关)
flink还提供了managed state来帮助用户简化使用, 在发生异常时会进行持久化, 之后可通过保存的数据进行任务恢复, 同时用户也可以使用row state, 自己实现序列化等操作
Managed State有如下几种
- ValueState[T]
- ListState[T]
- ReducingState[T]
- AggregatingState[IN, OUT]
- MapState[UK,UV]