LangGraph 是一个用于构建大型语言模型 Agent 的编排框架,它与 LangChain 深度集成,具备出色的有状态流程管理能力。在之前的文章中,曾介绍过如何使用LangGraph及MCP实现Agent 。在那篇文章中可以看到,得益于 LangGraph 内置的丰富组件,开发过程非常简洁。
本文将简要介绍 LangGraph 中常用的一些核心概念,帮助更好地理解和使用。如需详细内容,请参考官方文档
核心组件
State(状态)
State 是 LangGraph 中的数据结构,用于表示一次对话流程中的所有信息,例如用户输入、大模型响应等。通常我们通过继承 TypedDict 或使用 Pydantic 的 BaseModel 来定义 State:
1 2 3 4 5 from typing import TypedDictclass ChatState (TypedDict ): message: str response: str
我们将以一个简单的例子来展示如何使用 State 构建 LangGraph,可以先不关注其中的具体细节,只要看State 相关部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import osfrom langgraph.graph import StateGraphfrom langchain_core.messages import HumanMessageos.environ["DEEPSEEK_API_KEY" ] = "<deepseek-api-key>" from langchain_deepseek import ChatDeepSeekmodel = ChatDeepSeek( model="deepseek-chat" , temperature=0 , max_tokens=1000 , max_retries=2 ) def chat_node (state: ChatState ): resp = model.invoke([HumanMessage(content=state["message" ])]) return {"response" : resp.content} builder = StateGraph(ChatState) builder.add_node("chat_node" , chat_node) builder.set_entry_point("chat_node" ) builder.set_finish_point("chat_node" ) graph = builder.compile () for event in graph.stream({"message" : "简单介绍一下LangGraph" }, stream_mode="values" ): print (event)
输出结果如下,可以看出其中的 message 和 response 字段的值
1 2 {'message': '简单介绍一下LangGraph'} {'message': '简单介绍一下LangGraph', 'response': 'LangGraph 是 LangChain 生态中的一个库,专注于构建**有状态、多参与者的图结构应用**,尤其适合开发复杂的多步骤工作流或代持循环、分支等复杂逻辑。\n\n---\n\n### **核心特点**\n1. **基于图的编排** \n - 将任务分解为节点(Node),通过边(Edge)定义执行顺序,形成可循环、分支或并行的流程。\n如自主代理)。\n\n2. **状态管理** \n - 自动维护全局状态(State),节点间可共享和更新数据,简化多步骤任务的状态传递。\n\n3. **与LangChain深度集成** \n - 兼容LangC中使用。\n\n4. **多参与者协作** \n - 支持多个代理(Agent)或服务协同工作,通过图调度它们的交互(如辩论、分工)。\n\n---\n\n### **常见应用场景**\n- **自主代理(Auton **复杂工作流** \n 处理需要条件判断、回退或人工干预的多步骤流程(如客服自动化)。\n- **多代理系统** \n 协调多个代理协作完成任务(如辩论、竞拍、分布式问题求解)。\ngraph import Graph\nfrom langchain_core.messages import HumanMessage\n\n# 定义节点\ndef agent_node(state):\n # 调用LLM或其他工具处理输入\n return {"response": f"e[\'input\']}"}\n\n# 创建图\nworkflow = Graph()\nworkflow.add_node("agent", agent_node)\nworkflow.add_edge("agent", "agent") # 循环执行\n\n# 运行\nresult = workflow.ioke({"input": "Hello!"})\nprint(result) # 输出代理的响应\n```\n\n---\n\n### **与LangChain的关系**\n- **LangChain**:提供基础组件(链、工具、记忆等),适合线性或简单分**复杂、动态、有状态**的流程,适合需要循环或协作的场景。\n\n---\n\n### **适用人群**\n- 需要构建多步骤、自适应代理的开发者。\n- 对工作流编排、状态管理有复杂需求的场景。tps://langchain-ai.github.io/langgraph/)获取最新特性。'}
对于需要记录多次对话消息的state而言,需要改为message集合
同时需要提供一个reduce函数,来将新增的消息进行合并,而不是进行覆盖,这里使用内置的add_messages函数,具体可以看下如下实现
1 2 3 4 5 6 from typing import TypedDict, Annotatedfrom langgraph.graph.message import add_messagesclass ChatState (TypedDict ): messages: Annotated[list , add_messages]
修改后的节点函数如下:
1 2 3 4 5 6 7 8 9 10 11 from langchain_core.messages import HumanMessagedef chat_node (state: ChatState ): ai_message = model.invoke(state["messages" ]) return {"messages" : [ai_message]} for event in graph.stream({"messages" : [HumanMessage(content="简单介绍一下LangGraph" )]}, stream_mode="values" ): print (event)
输出结果,可以看到最后的输出中有两个Message, 一个 HumanMessage 以及一个 AIMessage
1 2 {'messages': [HumanMessage(content='简单介绍一下LangGraph', additional_kwargs={}, response_metadata={}, id='21278761-4b19-43bc-a5e4-d2f1b407f1c8')]} {'messages': [HumanMessage(content='简单介绍一下LangGraph', additional_kwargs={}, response_metadata={}, id='21278761-4b19-43bc-a5e4-d2f1b407f1c8'), AIMessage(content='aph 是 LangChain 生态中的一个库,专注于通过**图结构**(Graph)来构建复杂的多步骤工作流,尤其适合开发具备循环、分支等逻辑的大语言模型(LLM)应用。它结合了 LangChain 的核(Nodes)**:代表流程中的单个步骤(如调用 LLM、执行代码)。\n- **边(Edges)**:定义节点间的执行顺序,支持条件分支(`if-else`)和循环。\n- **状态(State)**:贯穿整个图 支持基于 LLM 输出或自定义逻辑的动态路径选择(例如,根据回答质量决定是否重试)。\n- **并行执行**: \n 可同时运行多个节点,提升效率。\n- **持久化状态**: \n 暂停并恢)。\n- **与 LangChain 集成**: \n 直接复用 LangChain 的链(Chains)、工具(Tools)等组件。\n\n---\n\n### **3. 典型应用场景**\n- **复杂对话系统**:根据用户输入动态调\n- **自动化流程**:审批流、数据处理等需要条件判断的场景。\n\n---\n\n### **4. 简单示例**\n```python\nfrom langgraph.graph import Graph\n\n# 定义节点\ndef step1(state):t"] + " 已处理"}\n\ndef step2(state):\n return {"result": state["data"].upper()}\n\n# 构建图\nworkflow = Graph()\nworkflow.add_node("process", step1)\nworkflow.add_finalize", step2)\nworkflow.add_edge("process", "finalize") # 定义执行顺序\n\n# 运行\noutput = workflow.execute({"input": "请求内容"})\nprint(output) # 输出: {\'resu\'请求内容 已处理\'}\n```\n\n---\n\n### **5. 优势**\n- **灵活性**:比线性链(Chain)更适应复杂逻辑。\n- **可视化**:支持图形化展示流程,便于调试。\n- **扩展性**:兼容 方文档进一步探索高级功能(如状态管理、异步支持)。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 552, 'prompt_tokens':'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 7}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '50478768-bdfc-41aa-8b2d-8ef19a222ee2', 'finish_reason': 'stop', 'logprobs': None}, id='run-d0bc5675-08a4-40c2-9da8-ec6efc461b1d-0', usage_metadata={'input_tokens': 7, 'output_tokens': 552, 'total_tokens': 559, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
Nodes(节点)
Node 是 LangGraph 中的基础执行单元,它是一个普通的 Python 函数,接收 state 作为输入并返回一个包含部分更新的字典:
比如上面例子中chat_node 就是一个大模型的节点,接收用户的输入,进行调用后返回结果
1 2 3 4 5 def chat_node (state: ChatState ): ai_message = model.invoke(state["messages" ]) return {"messages" : [ai_message]}
Node 也可以接受可选参数 RunnableConfig,以支持配置化执行:
1 2 3 4 5 6 from langchain_core.runnables import RunnableConfigdef say_hello_node (state: ChatState, config: RunnableConfig ): user_name = config["configurable" ]["user_name" ] return {"messages" : [AIMessage(content=f"你好 {user_name} !" )]}
重新构建一下LangGraph,替换一下对应的节点:
1 2 3 4 5 6 7 8 9 10 11 12 builder = StateGraph(ChatState) builder.add_node("say_hello_node" , say_hello_node) builder.set_entry_point("say_hello_node" ) builder.set_finish_point("say_hello_node" ) graph = builder.compile () for event in graph.stream({"messages" : [HumanMessage(content="你好" )]}, config=RunnableConfig(configurable= {"user_name" : "张三" }), stream_mode="values" ): print (event)
输出结果,可以看到正常输出了用户的user_name 信息
1 2 {'messages': [HumanMessage(content='你好', additional_kwargs={}, response_metadata={}, id='4c2a9e23-f2de-4fa5-856f-9fe4cd3a22b1')]} {'messages': [HumanMessage(content='你好', additional_kwargs={}, response_metadata={}, id='4c2a9e23-f2de-4fa5-856f-9fe4cd3a22b1'), AIMessage(content='你好 张三!', addi_kwargs={}, response_metadata={}, id='407f5839-47cc-4fee-a8c0-1fe43f66a310')]}
起始和结束节点
LangGraph 使用特殊的 START 和 END 常量定义图的入口和出口,可以通过add_edge添加入/出口与其他节点的连接,也可以使用更简洁的 set_entry_point() 与 set_finish_point() 方法,它们本质等价
1 2 3 4 5 6 7 8 from langgraph.constants import START, ENDbuilder.add_edge(START, "say_hello_node" ) builder.add_edge("say_hello_node" , END)
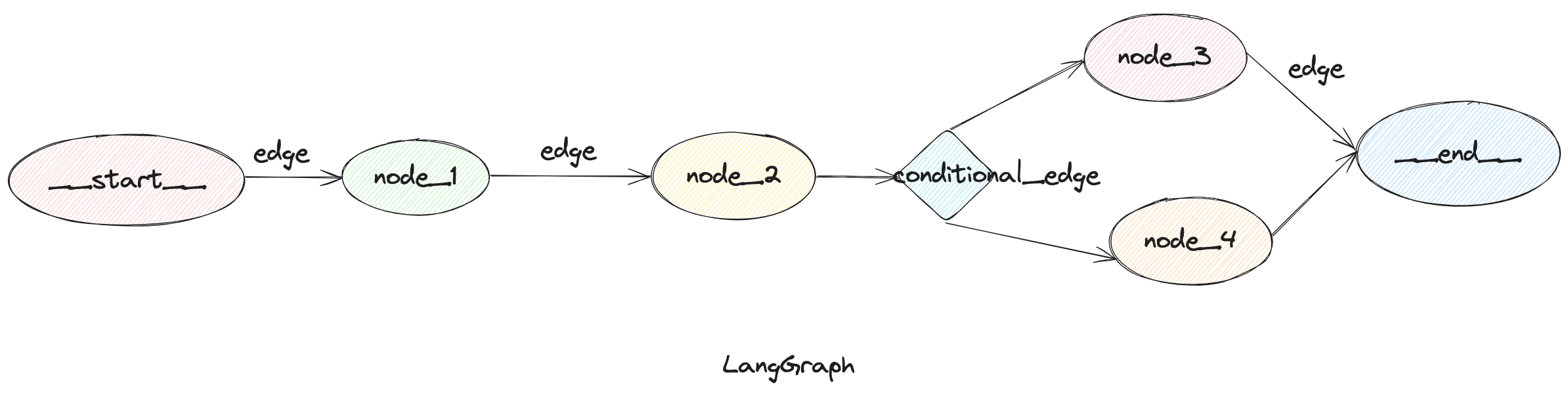
Edges(边)
边用于定义节点之间的执行关系
普通边
graph.add_edge("node_1", "node_2") 表示执行完node_1后一定会执行node_2
条件边
graph.add_conditional_edges(node_1, routing_func),表示执行完node1之后,会根据routing_func返回的节点名称进行路由
或者如果函数返回的内容和节点名称不匹配,可以在最后增加一个dict参数,将routing_func输出的结果映射到节点名称,如graph.add_conditional_edges("node_1", routing_func, {"key1": "node2", "key2": "node3"})
入口点
定义开始后执行的第一个节点,graph.add_edge(START, "node_1")或者graph.set_entry_point("node_1")
条件入口点
可以在开始执行时就进行条件路由,graph.add_conditional_edges(START, routing_func)
Memory(记忆)
默认情况下,LangGraph 在一次对话结束后不会保留 state 信息。如果需要多轮记忆能力,可以使用 短期记忆(short-term memory) 或 长期记忆(long-term memory) 。
如果我们希望Agent 记住的是上几轮的对话内容,这时我们需要的就是LangGraph提供的短期记忆(short-term memory)
而如果我们希望大模型能记住用户是一个什么样的人,后续可以提供更加个性化的回答等信息,那就需要用到长期记忆(long-term memory),下面我们来分别看下
短期记忆
通过 checkpointer 实现 state 的保存和恢复:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import osfrom langchain_core.messages import HumanMessagefrom langchain_core.runnables import RunnableConfigfrom langchain_deepseek import ChatDeepSeekfrom langgraph.checkpoint.memory import InMemorySaverfrom langgraph.graph import StateGraph, MessagesStateos.environ["DEEPSEEK_API_KEY" ] = "<deepseek-api-key>" model = ChatDeepSeek( model="deepseek-chat" , temperature=0 , max_tokens=1000 , max_retries=2 ) def chatbot (state: MessagesState ): resp = model.invoke(state["messages" ]) return {"messages" : [resp]} builder = StateGraph(MessagesState) builder.add_node("chatbot" , chatbot) builder.set_entry_point("chatbot" ) builder.set_finish_point("chatbot" ) checkpointer = InMemorySaver() graph = builder.compile (checkpointer=checkpointer) config = RunnableConfig(configurable={"thread_id" : "1001" }) for chunk in graph.stream(input ={"messages" : [HumanMessage("你好,我是张三" )]}, config=config, stream_mode="values" ): print (chunk) for chunk in graph.stream(input ={"messages" : [HumanMessage("你知道我的名字是什么吗?" )]}, config=config, stream_mode="values" ): print (chunk)
当然,这种情况下随时对话消息越来越多,有可能会导致消息内容超过了大模型的上下文限制,这时候可以通过消息的截取或者总结对话的方式,来缩短消息内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from langchain_core.messages.utils import ( trim_messages, count_tokens_approximately ) def chatbot (state: MessagesState ): messages = trim_messages( state["messages" ], strategy="last" , token_counter=count_tokens_approximately, max_tokens=1000 , start_on="human" , end_on=("human" , "tool" ), ) resp = model.invoke(messages) return {"messages" : [resp]}
消息总结的话,则需要在大模型节点之前增加一个单独的节点:SummarizationNode
1 2 3 4 5 6 7 8 9 10 from langmem.short_term import SummarizationNodesummarization_node = SummarizationNode( token_counter=count_tokens_approximately, model=model, max_tokens=512 , max_tokens_before_summary=256 , max_summary_tokens=256 , )
这样起始也没有完全解决问题,只是限制了在调用大模型之前对消息进行了处理,不会超过大模型本身的窗口限制,但是存储的消息体数量仍然是没有减少的,这时候可以通过RemoveMessage或其他方式直接修改status中的消息数据
长期记忆
长期记忆需要使用store来存储和获取信息,和checkpointer的区别是获取和设置值都需要手动编写代码来处理,这里简单列出一下使用方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from langgraph.store.base import BaseStorefrom langgraph.store.memory import InMemoryStorestore = InMemoryStore() graph = builder.compile (checkpointer=checkpointer, store=store) def chatbot (state: MessagesState, config: RunnableConfig, store: BaseStore ): resp = model.invoke(state["messages" ]) user_id = config["configurable" ]["user_id" ] namespace = ("memories" , user_id) memories = store.search(namespace, query=str (state["messages" ][-1 ].content)) store.put(namespace, str ("" ), {"data" : "ab" }) return {"messages" : [resp]}
Human-in-the-loop(人机循环交互)
在有了checkpointer后,就可以在图中执行的过程中中断节点,人工介入处理后,在继续执行的能力
比较适用于一些工具调用的确认,或者补充提供一些信息给大模型等,主要是通过 interrupt 和 Command来完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import osfrom langchain_core.messages import HumanMessagefrom langchain_core.runnables import RunnableConfigfrom langchain_deepseek import ChatDeepSeekfrom langgraph.checkpoint.memory import InMemorySaverfrom langgraph.prebuilt import create_react_agentfrom langgraph.types import interrupt, Commandos.environ["DEEPSEEK_API_KEY" ] = "<deepseek-api-key>" model = ChatDeepSeek( model="deepseek-chat" , temperature=0 , max_tokens=1000 , max_retries=2 ) def book_hotel (hotel_name: str ): """book a hotel""" response = interrupt(f"目前在尝试进行预订酒店: {hotel_name} ,请确认或重新输入酒店名称" ) if response["type" ] == "accept" : pass elif response["type" ] == "edit" : hotel_name = response["args" ]["hotel_name" ] else : raise ValueError(f"未知的响应类型 {response['type' ]} " ) return f"成功预定了酒店: {hotel_name} " checkpointer = InMemorySaver() agent = create_react_agent(model=model, tools=[book_hotel], checkpointer=checkpointer) config = RunnableConfig(configurable={"thread_id" : "1001" }) result = agent.invoke({"messages" : [HumanMessage("预定一天汉庭酒店住宿" )]}, config) print (result['__interrupt__' ])print (agent.invoke(Command(resume={"type" : "accept" }), config=config))
interrupt不仅可以用来tools中,也可以用来普通node节点中,通过人工输入的信息进行不同节点的路由
总结
LangGraph 是一个强大且灵活的流程编排框架,适用于多轮对话、复杂决策路径、Agent 协作等场景。它在 LangChain 基础上构建,兼容其生态系统,同时提供了图结构、状态管理、记忆机制等高级功能。
适用人群:
希望构建多步骤、可协作智能代理的开发者
有复杂逻辑需求(如循环、条件判断、并发执行)
需要对话记忆能力(短期 / 长期)的场景
更多内容请参考 LangGraph 官方文档 。