LLamaIndex顾名思义,看起来是一个适合构建索引的框架,也就是 RAG(Retrieval-Augmented Generation),所以我们本次主要看一下如何使用LlamaIndex 来实现一下RAG(当然,它也能用来实现智能体等功能)
RAG 的交互流程如下
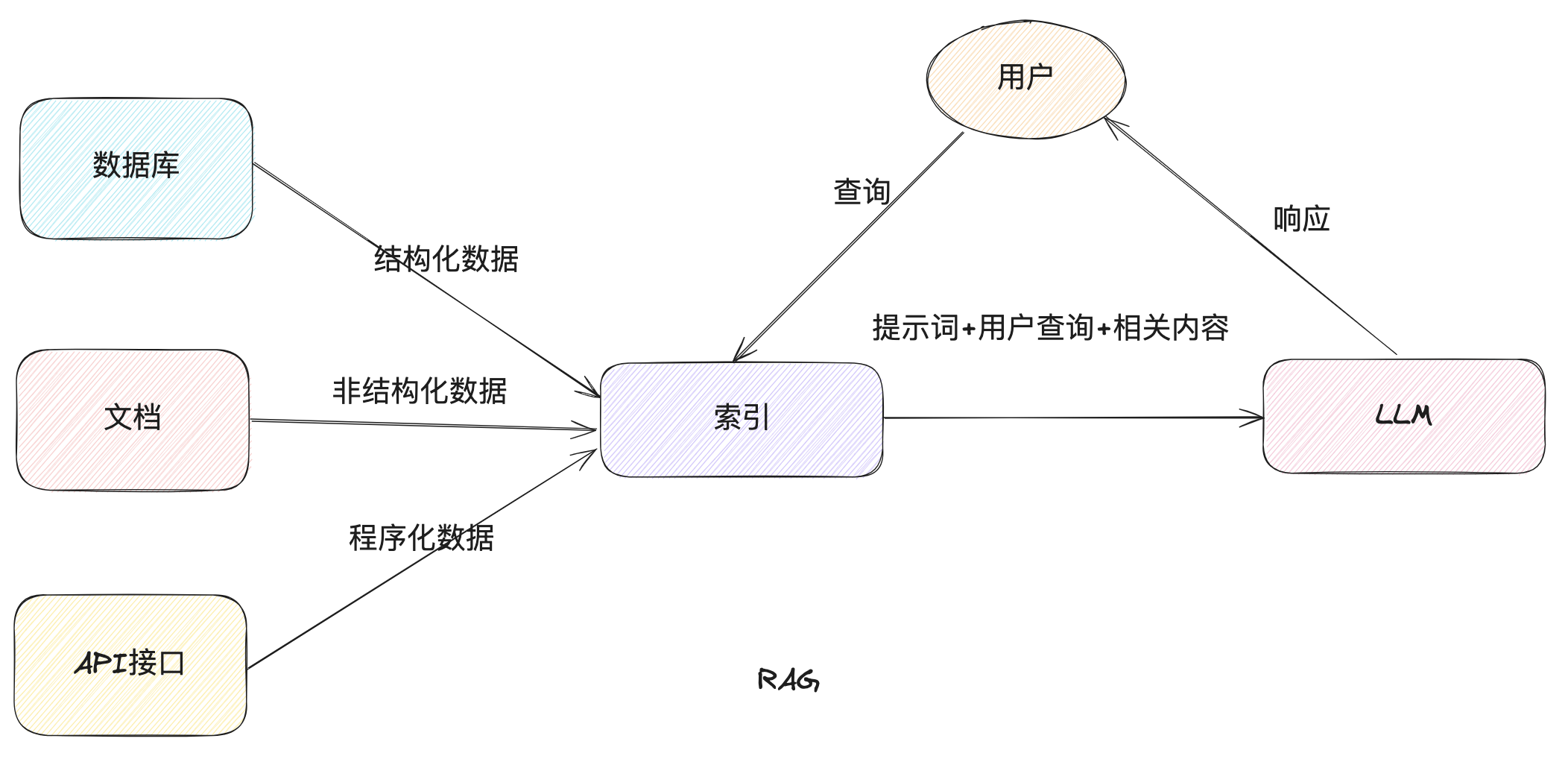
主要涉及如下几个步骤节点

快速使用
先通过一个例子快速感受一下如何使用,因为默认的OpenAI 的接口很难访问,这里使用阿里的dashscope
注册API 的部分参考官方文档即可,这里不再赘述
-
首先安装相关的依赖包
1
2
3pip install llama-index
pip install llama-index-llms-dashscope
pip install llama-index-embeddings-dashscope -
编写相关代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
from llama_index.llms.dashscope import DashScope
from llama_index.embeddings.dashscope import DashScopeEmbedding
# 分别创建文本和向量两个模型
dashscope_llm = DashScope(api_key="your-api-key")
embedder = DashScopeEmbedding(api_key="your-api-key")
# 将其设置为全局默认使用(否则会默认使用OpenAI相关模型)
Settings.llm = dashscope_llm
Settings.embed_model = embedder
# 手动构造document
documents = [Document(text="""
1. 火卫一绕火星运行
2. 火星是一种行星
3. 卫星绕行星运行
4. 火卫一(Phobos)以希腊恐惧与恐慌之神命名
5. 卫星位于太空中
6. 分类是一种科学过程
""")]
# 构建索引
index = VectorStoreIndex.from_documents(documents)
# 创建查询引擎
query_engine = index.as_query_engine()
# 提出问题,查询问题对应结棍
response = query_engine.query("火卫一应该归类为什么类别?")
输出结果:火卫一应该归类为卫星。
概念介绍
下面根据官网文档,来对RAG流程中涉及到的一些概念进行介绍
数据加载
文档和节点
文档(Document):是一个数据源的容器,数据源可以包括一个PDF, 一个 API 输出,甚至是从数据库中获取的数据
可以手动构建 Document 也可以通过工具自动构建
一般除了基本文本内容外,也会记录其他属性信息,如元数据(文件名称等)以及和其他内容的关联关系
手动构建方式:
1 | from llama_index.core import Document |
本地文件加载:
1 | from llama_index.core import SimpleDirectoryReader |
其他更多数据加载器(Reader),可以通过Llamahub查询获取
节点(Node):是LlamaIndex 中的基本数据单元,用来表示Document 的一个块(chunk),如文本块、图片等等,同Document 一样会记录元数据以及和其他Node 的关联关系
可以直接指定内容和属性来构造Node,也可以通过解析器来将Documents 处理成Node,如NodeParser
解析Document为Node集合:
1 | from llama_index.core.node_parser import SentenceSplitter |
手动构建Node:
1 | from llama_index.core.schema import TextNode, NodeRelationship, RelatedNodeInfo |
元数据转换:目前已经预置了如下几个元数据转换器,用于处理时提取对应的信息
- SummaryExtractor: 对每个节点内容进行总结,添加到metadata中
- QuestionsAnsweredExtractor:针对节点内容,提取出对应数量的问题添加到metadata中
- TitleExtractor:根据节点内容生成标题,添加到 metadata中
更多的转换器,可以参考官方文档-extractors
1 | from llama_index.core.extractors import TitleExtractor |
索引
索引可以让我们快速的根据用户的问题查询到对应的相关内容
索引可以通过Document构建,后续用来创建Query Engines和Chat Engines来使用
向量存储索引
通过document直接构建向量索引
1 | from llama_index.core import VectorStoreIndex |
通过nodes构建向量索引
1 | from llama_index.core.schema import TextNode |
在将文本转换成向量时,需要用到大模型的能力,默认会使用OpenAI的text-embedding-ada-00,如果我们要使用阿里的dashscope,则可以进行如下配置
-
安装依赖
pip install llama-index-embeddings-dashscope -
构造
DashScopeEmbedding并设置为全局默认
1 | from llama_index.embeddings.dashscope import DashScopeEmbedding |
在索引创建完成之后,我们也可以继续对其进行修改
1 | # 向索引中添加新Document |
更多其他类型索引文档,可以参考官方文档-indexing
存储
因为构造索引需要调用大模型的API,为了节省成本我们可以将索引进行持久化,在后续使用的时候重新加载即可
1 | from llama_index.core import StorageContext, load_index_from_storage |
这里也可以使用专门的向量数据库,具体使用方式可以参考官方文档
查询
检索器
检索器负责根据用户的查询/对话,查询到最相关的内容
可以通过索引直接构建
1 | # 通过索引构建检索器 |
路由
在有多个检索器的情况下,可以使用路由来决定具体使用哪个检索器来进行相关内容的查询
1 | from llama_index.core.retrievers import RouterRetriever |
节点后处理器
在通过检索器获取到数据,到提交给大模型处理返回之前,可以添加一些节点来对数据结果进行一些处理,如转换、过滤或者重排序
1 | from llama_index.core.postprocessor import SimilarityPostprocessor |
更多预置节点可以参考官网文档-node_proessors
响应合成器
结果合成器,是负责将用户问题和检索到的一系列文本块提供给大模型,生成最终结果使用
1 | from llama_index.core.data_structs import Node |
其中可选的 response mode 包括:refine、compact、tree_summarize、simple_summarize、no_text、context_only、accumulate、compact_accumulate、generation 等。每种模式的区别如下:
- refine:逐块精细生成和迭代答案,适合需要详细、分步推理的场景;
- compact:将多个块合并后生成答案,减少 LLM 调用次数,适合大文本但对细节要求不高的场景;
- tree_summarize:递归树状摘要,适合多块内容的总结;
- simple_summarize:截断所有块合并为单次 LLM 调用,适合快速摘要但可能丢失细节;
- no_text/context_only:仅返回检索到的节点或拼接文本,不生成最终答案,适合调试或需要原始上下文的场景;
- accumulate/compact_accumulate:分别对每个块单独问答并拼接,适合需要分别处理每个块的场景;
- generation:忽略上下文,直接用 LLM 生成答案,适合开放式生成任务。官方文档有详细说明。
最后,可以将检索器和响应合成器合并成查询引擎,输入用户问题,获取最终加工后的结果,完整代码如下
1 | from llama_index.core import VectorStoreIndex, get_response_synthesizer |
也可以通过更简化的方式,直接通过索引来构造查询引擎
1 | query_engine = index.as_query_engine(response_mode="tree_summarize") |