我们开发的每一个需求,基本 80% 的时间在搞清楚该改什么,只有 20% 在写代码。这不是能力原因,更是在于软件的复杂度
一个似曾相识的场景
比如接到需求:结算单状态机增加一个「部分退款」中间状态
在梳理了 SettlementService、SettlementController、SettlementStateMachine 后,改动范围很清楚——加一个枚举值,改三条状态流转路径。改动量很小,代码 review 也顺利通过。
结果上线第二天,告警来了:对账报表里部分退款的结算单被重复计入
问题出在一个没人知道的类——ReconciliationReportBuilder。它内部有一个 switch-case 遍历结算单状态来决定归入哪个科目,新增的枚举值走到了 default 分支,被当成「已结算」处理了
这个类的存在,在改代码的时候可能完全不知道。甚至不知道「我应该知道它的存在」
如果你在接手业务需求的时候也踩过类似的坑,这篇文章就是写给你的
复杂度不是代码行数多,而是「改起来费劲」
先澄清一个常见的误解:复杂度 ≠ 功能多、代码量大。
一个 50 万行的系统,如果你的 IDE 能帮你在一秒内定位到所有需要修改的地方,且你改完有充分信心不会遗漏——那这个系统就不算复杂。反过来,一个 5000 行的模块,如果每次改一个 if 条件你都要把 3 个相关服务翻一遍才敢动手——它就是复杂的
由此可以给复杂度下个定义:任何由系统结构导致的、使你难以理解和修改代码的东西,都是复杂度
这个定义的价值在于,它把衡量标准从「代码长什么样」转移到了「你改代码的时候经历了什么」。而你的经历通常对应下面三种症状之一
症状一:变更放大
一个看似微小的需求变更,要修改大量代码。
Java 后端最普遍的例子:给一个接口的返回值加个字段。你要改 Controller 的参数校验、Service 的组装逻辑、DTO 的字段定义、DAO 的 SQL 映射、MyBatis 的 XML、单元测试的 mock 数据、集成测试的断言——七八个文件改下来,核心逻辑其实只加了一行赋值
更隐蔽的情况是,业务对象的一个核心属性(比如订单状态、账户类型)被几十个地方 switch-case 分散引用。这时候状态机加一个节点,改代码本身不累——累的是你要先找全这几十个引用点
症状二:认知负荷
要完成一个改动,你必须先搞懂多少东西
举个找上门的例子:你新接手一个订单服务,要给查询接口加一个过滤条件。你以为只是给 SQL 加一个 AND status = ?,结果发现:
- SQL 是 MyBatis 动态 XML 拼出来的,3 层
<if>嵌套决定哪个条件生效 - 入参从 Controller → Service → Manager → DAO 传了 4 层,每一层都在改名
- 中间还有一个 AOP 切面在做数据权限过滤,会偷偷替换参数
- 同一个 Service 方法被 6 个定时任务和 3 个 MQ 消费者调用了,改了查询逻辑是不是等于改了定时任务的行为?
你原本只想加一行过滤条件,最后花了两天时间确认不会误伤其他调用方
认知负荷高,就不只是慢——它会让你更容易犯错。 需要记住的信息越多,遗漏关键约束的概率就越大
症状三:未知的未知
这是最致命的
开头的对账报表例子就是典型案例。ReconciliationReportBuilder 不在结算域里,不叫 Settlement- 开头,没有任何注释提到它依赖结算单的状态枚举。如果完全不知道它的存在,也就无从评估改动的影响范围
未知的未知不能靠「仔细」来预防。 人的认知边界由已知信息决定——你不可能去「仔细检查」一个你不知道存在的东西。系统越大,你越不可能在每次改动前读完所有代码
拆解复杂度:两个根因
为什么会产生这三种症状?回到根因,复杂度只来自两件事:依赖和莫名
依赖
当一段代码无法被单独理解和修改的时候,依赖就存在了
在 Java 项目里,依赖无处不在:服务间的 RPC 调用、DTO 对数据库表结构的映射、上游参数格式对下游的隐式约束、两个模块共享同一个枚举值的 switch-case
依赖不可能消除——它是软件的本质属性。 设计的目标不是消灭依赖,而是让依赖更少、更简单、更显然
一个经典案例:早期网站在每个页面各自定义了横幅背景色。想改颜色?几十个页面逐个改。背景色在每个页面之间建立了「不显然」的依赖——没有一个集中的地方告诉你哪些东西被关联在一起。改进方案是在一个中心位置定义颜色变量,各页面引用它。依赖从「几十个页面间」降到了「每个页面和一个中心变量之间」,而且变量名可全局搜索,依赖关系变得显然
对应的 Java 场景:与其让十几个服务各自维护一份「订单状态 → 可执行操作」的映射表,不如在公共模块里用一个枚举统一表达
莫名
当重要信息没有出现在它应该出现的地方,就是莫名
看一个典型的 Java 方法签名:
1 | public void process(Long id, int timeout, boolean async); |
id是什么的 id?订单还是用户?timeout单位是毫秒还是秒?0 代表永不超时还是立即超时?async = true和false的行为差异是什么?返回值去哪了?
这些问题的答案不在方法签名里,不在注释里——你要读实现代码才能知道。而读实现代码的成本就是认知负荷
还有一种更隐蔽的莫名:两个 Service 通过 Redis key 做隐式通信。A 服务写 order:lock:123,B 服务读到这个 key 就跳过某个处理分支。这种依赖不出现在任何接口签名、参数列表或注释中,但它真实存在于系统的运行时行为里。下一个接手 B 服务的人可能永远不知道"为什么有时候这个分支不执行"
依赖 + 莫名同时出现,就是未知的未知的温床。 依赖让你必须知道某件事,莫名让你不知道你需要知道这件事
解法一:让模块变深,而不只是变小
「模块要小、类要小」——这是 Java 后端面试和培训里被重复最多的话。但小不等于好。一个更好的度量标准是深度
把每个模块想象成一个矩形:
顶部边线 = 接口复杂度,越窄越好
矩形面积 = 提供的功能量,越大越好
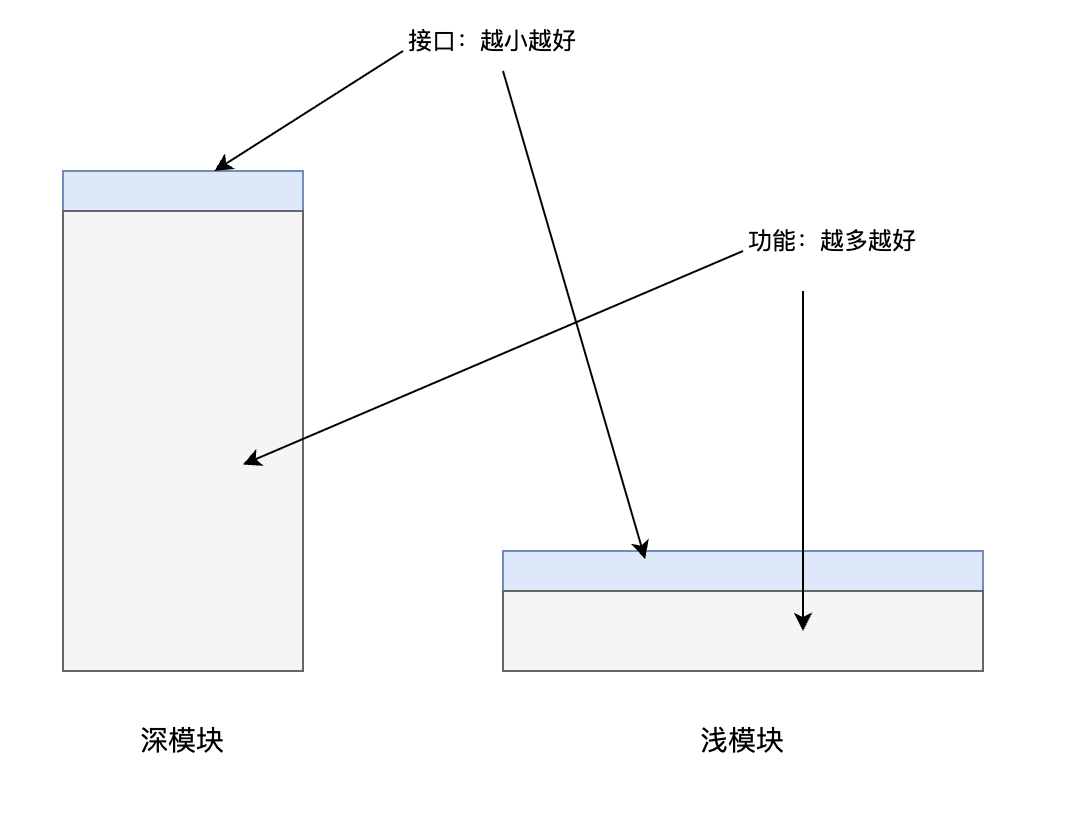
- 深模块:接口窄小,功能强大。大量复杂性封在实现中,使用者只需理解接口
- 浅模块:接口宽大,功能有限。读接口和读实现一样费劲,模块退化为「代码的分类摆放」
Java 后端的头号浅模块:万能 Service
1 |
|
这个 Service 表面在做「分层」——Controller 不直接调 Mapper。但它的每一个方法都没有隐藏任何信息,也没有封装任何复杂性。接口面积巨大(20 个 public 方法),功能深度趋近于零——你读它的接口和读 Mapper 的接口没有本质区别
更糟糕的是,这种「薄 Service + 薄 DAO」的写法会繁殖。系统中出现 50 个这样的 Service 之后,每个 Service 都有 20 个入口,全局的接口总面积爆炸式增长。这就是类泛滥——类多,接口更多,但没有一个替使用者消化了复杂度
一个好的深模块长什么样
1 |
|
调用方只需要知道一件事:settle(order) 执行结算。内部有多少步骤、每个步骤依赖哪些外部服务、出现异常如何回滚——全部被封装在模块内部
深模块的检验标准很简单:如果你要把这个模块的所有调用方团队召集起来开一个会,解释这个模块的用法,你能不能在 5 分钟内讲完?能,接口够窄。反过来如果需要一小时的培训——接口太宽了,复杂度泄漏了
解法二:把复杂度往下推,不要往上抛
模块的接口简单,比实现简单更重要
因为模块的使用者远多于开发者。一个 Service 可能有几十个调用方——把复杂度留在内部实现里,痛苦一次;暴露到接口上,让所有调用方跟着痛苦
滥用配置参数:典型的「向上推」
1 |
|
每个调用这个接口的人都要理解批次大小、超时、重试、存储方式这些实现细节。更可怕的是,如果某天你改了默认值,所有前端可能都要跟着改
好的设计是做正确的事,不需要被显式要求:
1 |
|
异常往上抛:另一个重灾区
1 | public void processPayment(Payment payment) throws PaymentException { |
调用方被迫为每一种异常写 catch 分支,而这些分支的行为千篇一律——打日志、返回错误码。如果调用方对异常的唯一处理就是 log.error,这个异常就不应该存在
更好的方式是内部消化,或使用统一的结果对象:
1 | public PaymentResult processPayment(Payment payment) { |
这个做法背后有一个更根本的原则:定义消除错误——不写更多异常处理的代码,而是重新设计接口的语义,让异常条件不再需要被处理
这和 Unix 删除已打开文件的逻辑一样:不报错,标记文件为「待删除」,等所有句柄关闭后自动释放——两种错误条件(删除失败、进程读写中断)同时被消解了
解法三:让系统「显然」
对付「未知的未知」,唯一有效的策略是让系统变得显然——一个不熟悉代码的人,能通过阅读接口和注释快速推测出改动范围,并且大概率猜对
命名精确到不需要解释
time 和 timeoutMillis 是两个完全不同的名字。前者需要你去看单元测试才能猜出含义,后者写在方法签名里就是一篇微型文档
getOrder() 和 fetchOrder() 和 queryOrder() ——在一个系统里,这三者应该是一个意思,还是各有分工?如果团队成员对这个问题有不同答案,认知负荷就产生了。选一个,全部统一
注释写「为什么」,不写「是什么」
1 | // 不好:重复代码 |
方法签名已经告诉了「是什么」(入参类型、返回类型)。注释的价值在于补充「为什么」和「小心什么」——前置条件、副作用、边界行为、调用顺序约束。这些是接口的「非形式部分」,编译器检查不了,但没有它们使用者就会踩坑
每个设计决策只记录一次
如果你发现同一条信息被两处注释重复描述,其中一处迟早会过时。找到一个最自然的位置——通常是变量声明处或方法接口注释处——写清楚,其他地方用 @see 引用
一致性是最廉价的复杂度削减
同一个概念,在所有模块里用同一个名字。相同的错误处理模式,不要在 A 模块抛异常、B 模块返回 null、C 模块返回 Optional。相同的分层约定——不要这个 Controller 直接调 DAO,另一个又走完整的 Controller → Service → Manager → DAO 链路
一致性的意义在于:读者只需要学一次规则,之后在系统的任何地方都能复用这个认知
解法四:每次改动后,让系统像一开始就为这个需求设计的
这是最后一个也是最重要的一条。它不是一个技术,而是一种纪律。
日常开发中有两种截然不同的做事方式:
- 战术性改动:最快的方式让功能跑起来。加一个 if,再加一个 if,能不动的地方坚决不动。
- 战略性改动:动手前先想——如果这个需求一开始就知道,当前的模块结构应该长什么样?如果不一样,先调整结构,再写功能代码
战术性改动的诱惑极大。面对 deadline,你只想加一行代码解决问题,而不是重构一个模块。毕竟重构有风险、需要测试、需要 review
但问题在于,复杂度就是由一千次"只加一个 if"累积起来的。 六个月后,那个类里塞了 40 个 if-else,没有人看得懂原始的逻辑流。新接手的人只能往上加第 41 个 if——因为重构的代价已经大到不可承受了
一个务实的操作原则:如果「正确的重构」需要三个月而「权宜之计」需要两小时,你可以妥协。但在此之前,先问自己一个问题——有没有一个方案,几乎一样干净,但只需要几天? 这个问题的答案往往比「两小时」和「三个月」这两个极端更好
不需要追求一步到位的完美,但要确保每次改动后,代码质量不低于改动之前。即使这次改动本身不需要重构,顺手修一个变量命名、删一段死代码、在关键位置补一行注释——这些微小的改善积累起来,就是正向循环
一张清单
把这篇文章的核心提炼成 5 个问题,每次改代码前花 30 秒自问一遍:
| # | 问题 | 你真正在关心什么 |
|---|---|---|
| 1 | 这个改动让我改了多个文件/方法?能不能收敛到一个? | 变更放大 |
| 2 | 一个不认识这段代码的同事,看完接口能不能猜对怎么用? | 认知负荷 / 显然 |
| 3 | 有没有"我不知道需要知道"的逻辑被我漏了?能不能加一行注释让下一个接手的人不踩坑? | 未知的未知 |
| 4 | 我是不是把复杂度留给了调用方(传一堆参数、处理各种异常、记住调用顺序)? | 向下推复杂度 |
| 5 | 改完之后,代码是比之前更容易维护了,还是更困难了? | 战略性改动 |
好的软件设计不是玄学。它就是每天在做的选择——是加一个 if,还是重构一个结构;是把配置参数甩给调用方,还是自己消化掉复杂度;是「反正功能通了」,还是让下一个接手的人少踩一个坑
本文的内容核心思想框架来自 John Ousterhout 的《A Philosophy of Software Design》,推荐阅读原著