原文:https://blog.langchain.com/how-to-build-an-agent/
本文介绍了当我们有了想法之后,如何通过一系列的步骤来逐步实现一个agent 的过程
其中主要侧重思路和过程,不涉及具体的技术实现细节
下面内容为对原文的理解翻译学习,大家可以优先考虑阅读原文
原文:https://blog.langchain.com/how-to-build-an-agent/
本文介绍了当我们有了想法之后,如何通过一系列的步骤来逐步实现一个agent 的过程
其中主要侧重思路和过程,不涉及具体的技术实现细节
下面内容为对原文的理解翻译学习,大家可以优先考虑阅读原文
LLamaIndex顾名思义,看起来是一个适合构建索引的框架,也就是 RAG(Retrieval-Augmented Generation),所以我们本次主要看一下如何使用LlamaIndex 来实现一下RAG(当然,它也能用来实现智能体等功能)
RAG 的交互流程如下
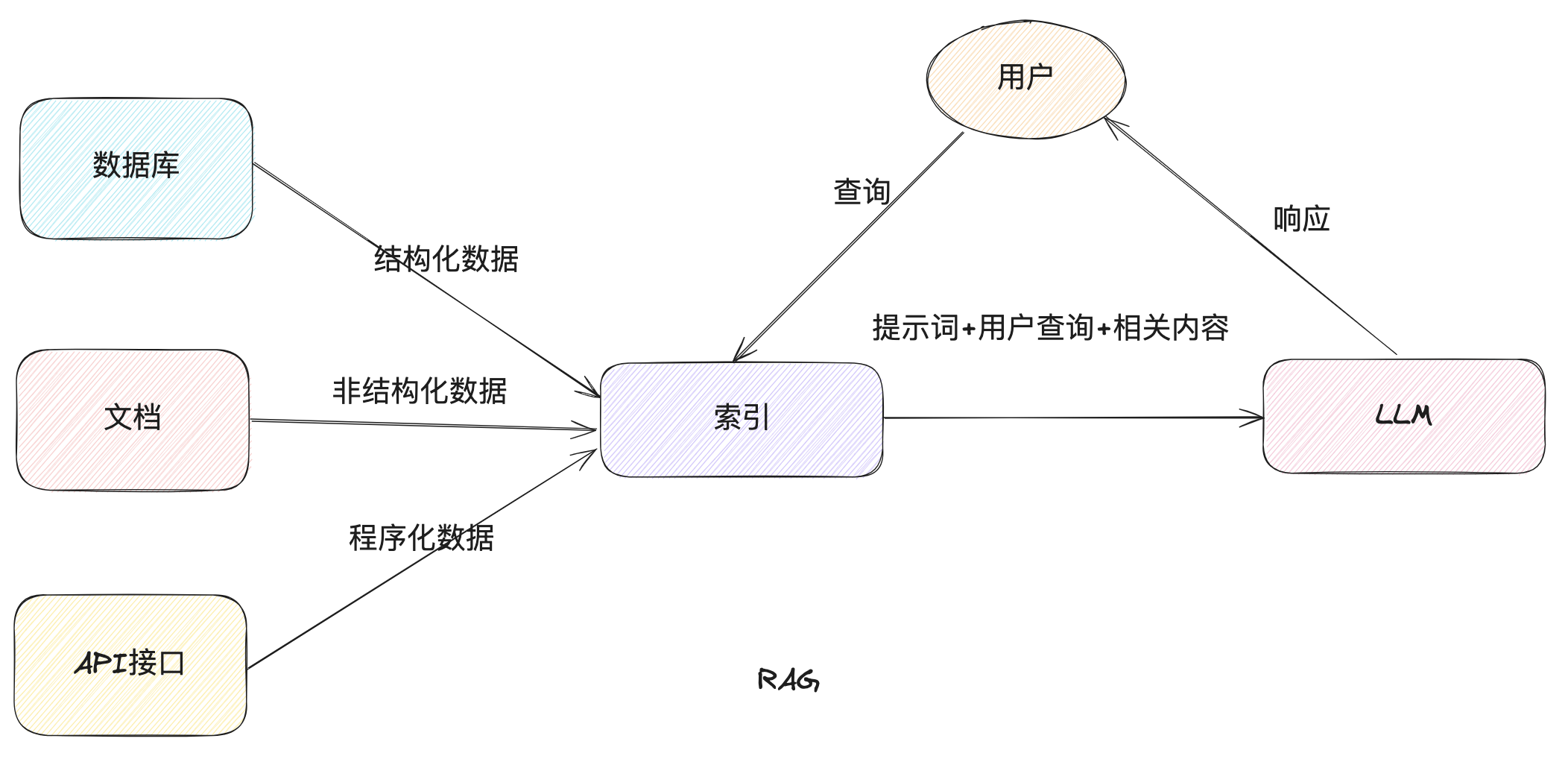
主要涉及如下几个步骤节点

LangGraph 是一个用于构建大型语言模型 Agent 的编排框架,它与 LangChain 深度集成,具备出色的有状态流程管理能力。在之前的文章中,曾介绍过如何使用LangGraph及MCP实现Agent。在那篇文章中可以看到,得益于 LangGraph 内置的丰富组件,开发过程非常简洁。
本文将简要介绍 LangGraph 中常用的一些核心概念,帮助更好地理解和使用。如需详细内容,请参考官方文档
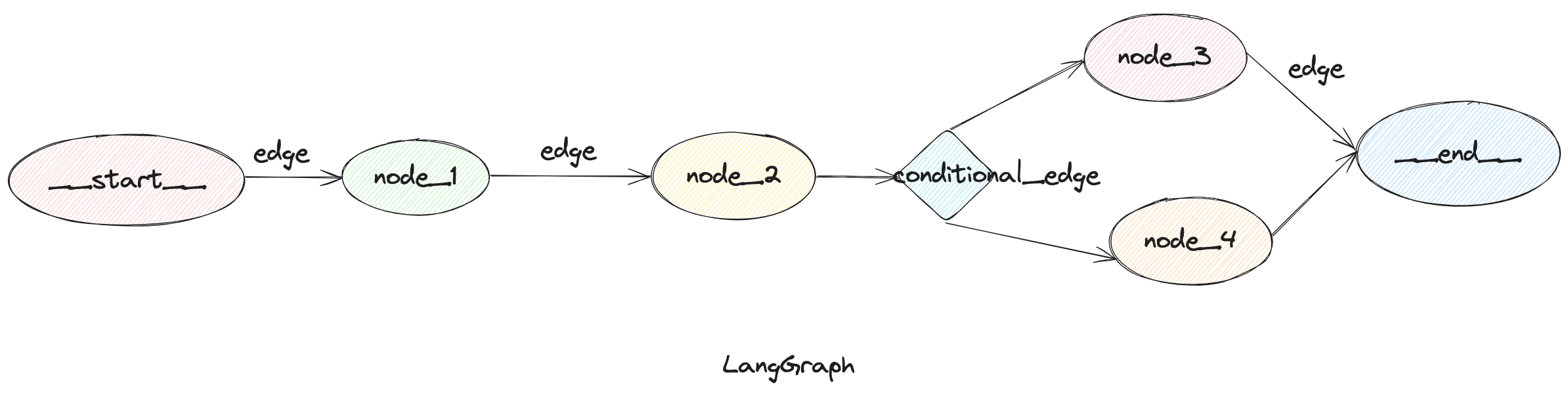
目前agent 大致有两种风格,一种是自己定义相应的工作流程(workflows),还有一种就是流程完全让大模型自己进行判断处理(agents)
本次主要简单记录一下使用langgraph 及mcp 实现一个 agents
这个可以认为是一个最简化工作流,只有llm 及tools 两个节点,当大模型判断需要调用tools 时就执行调用,直到大模型认为不需要调用工具,这时认为执行结束了,可以返回对应的结果
stateDiagram-v2
[*] --> Start
Start --> Agent
Agent --> Tools : continue
Tools --> Agent
Agent --> End : end
End --> [*]
交互流程
sequenceDiagram
participant U as User
participant A as Agent (LLM)
participant T as Tools
U->>A: Initial input
Note over A: Messages modifier + LLM
loop while tool_calls present
A->>T: Execute tools
T-->>A: ToolMessage for each tool_calls
end
A->>U: Return final state
感知机是一种监督学习算法,用于解决线性可分(Linearly Separable)的二分类问题,具体内容如下:
计算预测值:$z=w_1x_1 + w_2x_2 + b$
激活函数为阶跃函数:
参数更新函数:
《白话机器学习中的数学》笔记
机器学习主要擅长包括回归、分类、以及聚类任务
回归是一种预测性的建模技术,用于确定一个或多个自变量(特征)与因变量(目标值)之间的关系,重点预测的是连续的数值。如根据房子的各类信息,预测房屋的价格
分类是将样本划分到不同的类别中,每个类别通常对应一个特定的标签,它是离散的、无序的。如根据邮件的信息判断其是否是垃圾邮件
聚类是将数据集中的样本划分成不同的组,使得同一组内的样本相似度高,而不同组之间的样本相似度低。聚类的结果事先是未知的,算法需要自行发现数据中的潜在结构。比如电商平台对客户进行分组,高消费、低消费等等。同时它和分类的区别就是它是无监督学习,而分类是有监督学习(可以认为是需要提供有正确答案的数据来学习)
这篇文章我们主要来学习一下其中的回归任务
这里需要先介绍一下Function calling,什么是Function calling? 它提供了可以让我们把大模型和外部数据或系统进行连接的能力
举个具体的例子:我们现在有一些如查询订单等信息的接口,我们可以把这些接口工具及参数等详情信息提供给大模型,这样如果在上下文对话中,它判断出需要需要使用这个接口时,就会返回对应的接口及参数值**(注意:大模型只是会判断后返回工具名称和参数,并不会实际进行调用)**
我们可以据此在本地进行实际的调用,获取最终结果进行返回;如果大模型函数不需要这个能力,那么就可以以正常自然语言的方式进行对话内容返回
当然,我们也可以通过设置一些参数,强制大模型使用/不使用工具
这个Function calling能力,各个大模型提供的api可能有所差异,需要看各自对应的API,但是langchain帮我们整合了相关的功能,所以本次我们主要看一下通过它来实现
大模型中一般可以用来进行对话等,但是有一些场景我们可能要基于大模型的返回结果进行一些后续代码的处理,比如进行一些判断,返回结果为是/否,或者生成一些数据我们直接使用,这种情况下我们就需要大模型返回的结构是固定的,这样代码才能够进行解析使用
本篇根据langchain官方文档,简单介绍一下如何使用langchain来让大模型返回结构化数据的几种方式
使用python 3.10.9 langchain0.3,以及百度千帆模型