问题
发现系统调用HTTPS接口时出现异常,异常信息如下
1 | javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: |
排查
怀疑1: 接口提供方的证书过期了?(其实仔细看日志的话就可以排除这个可能)
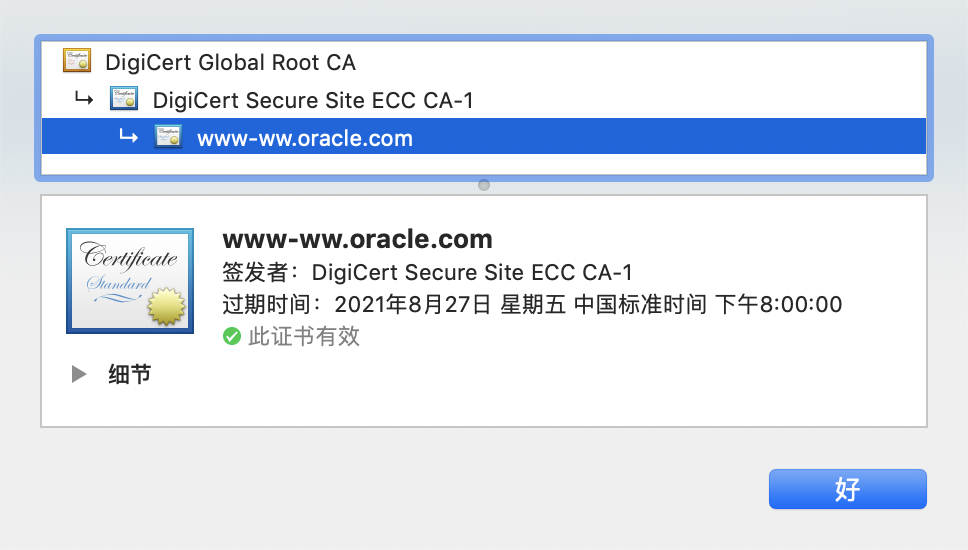
操作: 通过本地浏览器打开对应url,浏览器显示正常的安全信息,证书也未过期,oracle的证书样例如下(例子中的根证书颁发机构为 DigiCert Global Root CA ),这时可以排除证书问题