之前简单分析过定时任务的几种实现,但是都是单机本地的实现,现在看一下分布式的任务调度,开源的xxl-job的实现,因为其中的内容较多,这次我们就只看一下其中的任务调度部分,没有关注其中的一些分支逻辑,虽然也很重要
xxl-job的整体执行流程如下图所示
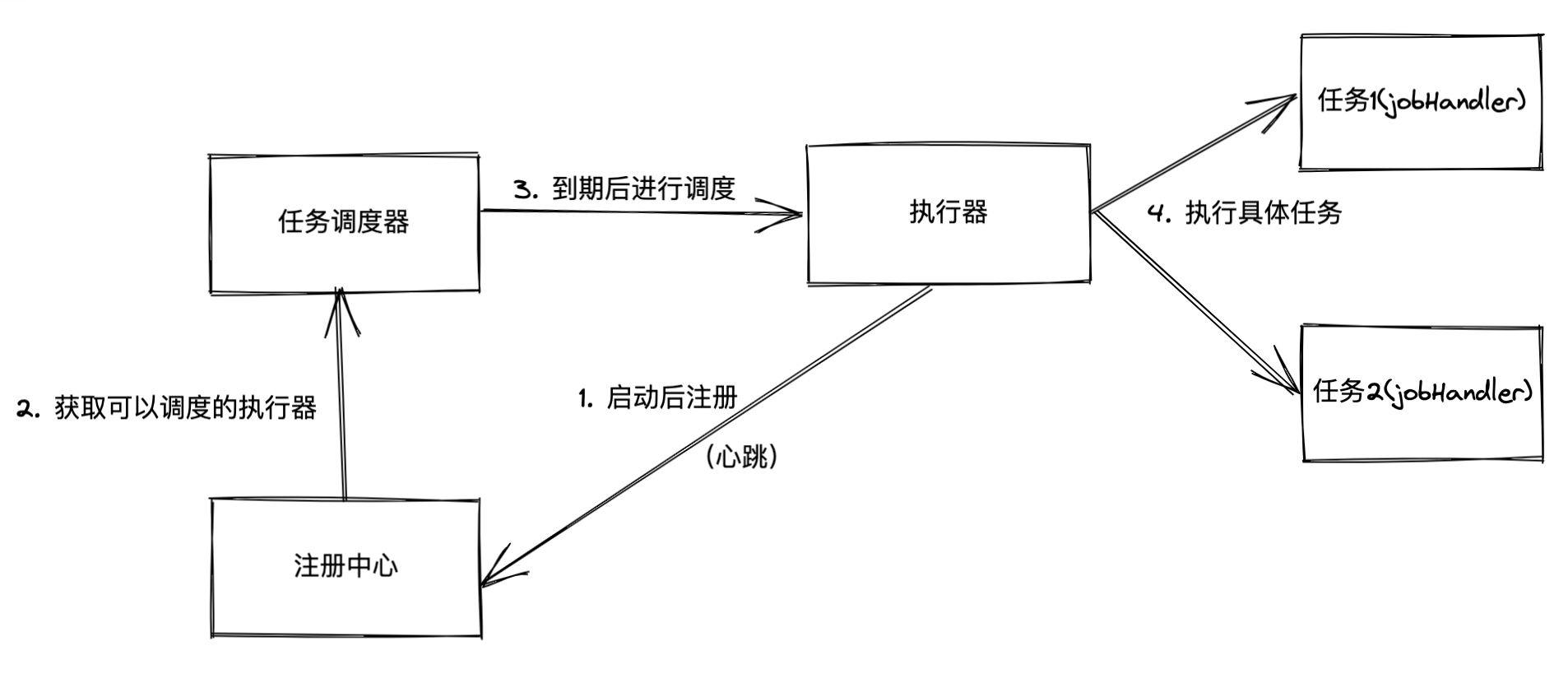
其中主要分为调度器和执行器,调度器用来根据配置信息,在特定的条件下调用执行器中的对应任务进行任务的执行
执行器配置
可以看一下xxl-job提供的spring boot为例的执行器,其中需要配置执行器的名称等信息
1 | # 设置调度中心的地址(执行时会有一些接口相关的调用交互) |
配置好执行器后,则需要进行其中的任务开发,例子代码如下
1 |
|
执行器注册
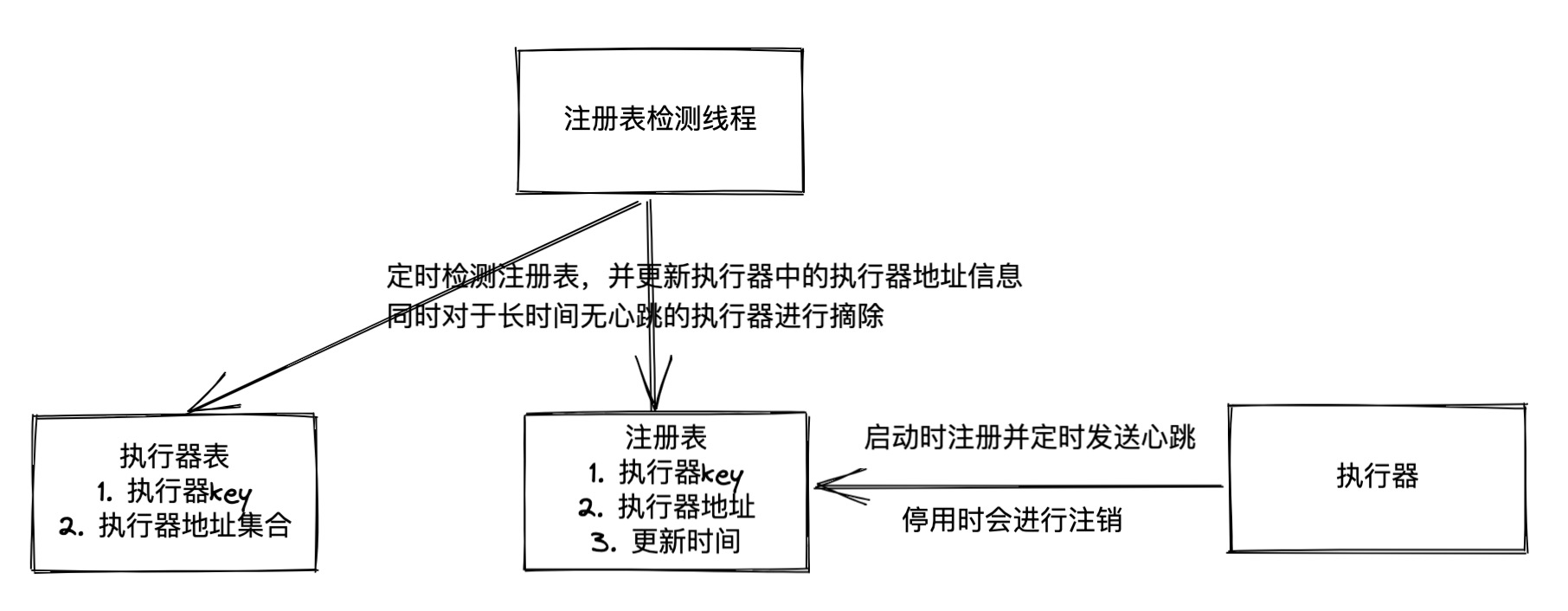
在执行器启动时,执行器会根据配置的调用中心地址,调用对应的接口了实现执行器的注册(以便后续调用器进行调度),注册后每隔30S还会进行一次心跳,证明自己还活着,在关闭时也会调用接口将自己摘除
xxl-job整体没有使用zookeeper之类的注册中心,在接收到执行器的注册请求后,会新增(更新)执行器的信息到对应的MySQL表(xxl_job_registry)中,同时在接收到心跳请求时更新其中的update_time字段
调用中心内部有一个检测线程,每隔30S检测一次,当发现有执行器3次都没有心跳(当前时间 - 最后一次更新时间 > 30S)时,认为这个执行器已下线,此时删除对应的记录(同时也会更新执行器记录中的执行器地址信息)
说完了执行器注册相关的功能,下面我们来看一下调度逻辑的实现
调度中心调度
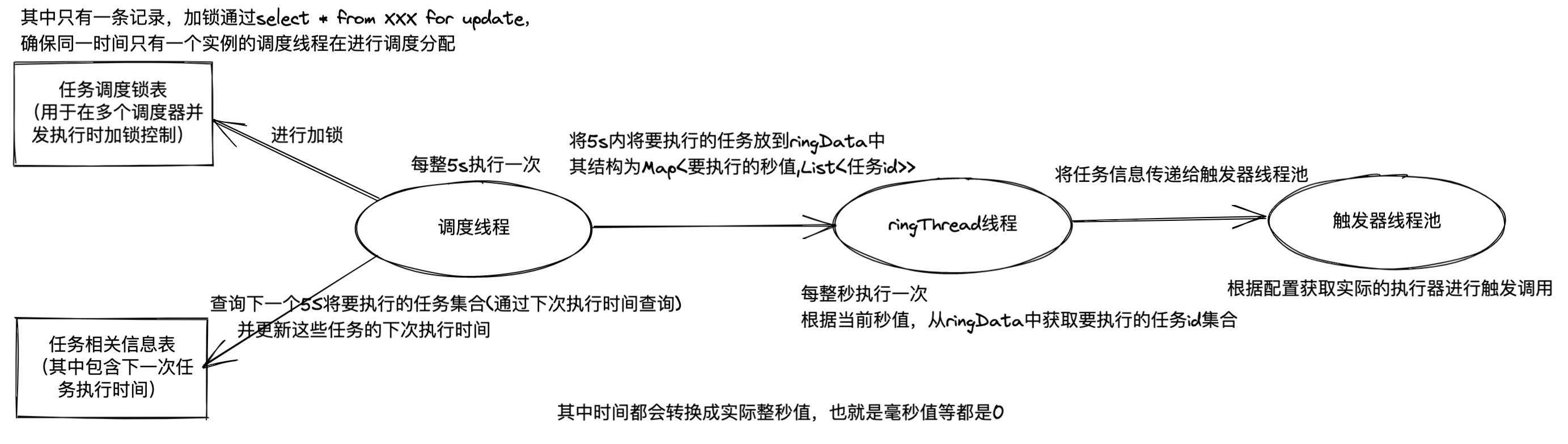
注册及调度主要流程基本如下,省略了特别多的细节,如有错误之处辛苦指正,感谢