《白话机器学习中的数学》笔记
机器学习主要擅长包括回归、分类、以及聚类任务
回归是一种预测性的建模技术,用于确定一个或多个自变量(特征)与因变量(目标值)之间的关系,重点预测的是连续的数值。如根据房子的各类信息,预测房屋的价格
分类是将样本划分到不同的类别中,每个类别通常对应一个特定的标签,它是离散的、无序的。如根据邮件的信息判断其是否是垃圾邮件
聚类是将数据集中的样本划分成不同的组,使得同一组内的样本相似度高,而不同组之间的样本相似度低。聚类的结果事先是未知的,算法需要自行发现数据中的潜在结构。比如电商平台对客户进行分组,高消费、低消费等等。同时它和分类的区别就是它是无监督学习,而分类是有监督学习(可以认为是需要提供有正确答案的数据来学习)
这篇文章我们主要来学习一下其中的回归任务
最小二乘法
对于简单的线性变化,可以定义一个一次函数,定义如下
$$
f_\theta(x) = \theta_0 + \theta_1 x
$$
假设 x 对应的实际值是 y,那么我们假设的 $\theta_0$和$\theta_1$计算后的值,与实际值的误差可以表示如下
$$
E(\theta)=\frac 1 2 \sum_{i=1}^n{(y^{(i)} - f_\theta(x^{(i)}))}^2
$$
当我们找到
$\theta$值可以使
$E(\theta)$的值也就是误差最小,那么这个就是求得的最佳结果
最速下降法
为了找到误差最小值,可以使用斜率的方式,向斜率更低的方向去寻找,找到斜率最低的点,这时候可以使用微分
$$
如:g(x)=(x-1)^2=x^2-2x+1, 对应的微分为:\frac d {dx} g(x) = 2x-2
$$
这种方式可以称为最速下降法或者梯度下降法,对应公式
$$
x := x - \eta \frac d {dx}g(x)
$$
其中
$\eta$表示的为学习率,设置好初始值之后,每次计算结果更新
$x$后再次计算下一个
$x$
可以简单理解为在不同区间用学习率乘以导数获取对应位置移动的距离,当在一个区间,斜率基本为0 时,也就是两次x 值基本无变化,即可认为找到了解
当设置的学习率过低时,需要学习找到最佳值的次数就会很多,过高时,会有可能直接越过了最大值,左右两侧区间来回无限循环了
现在要做的就是来计算一下斜率$\frac d {dx} f(x)$,因为其中涉及了 $\theta_0$和$\theta_1$两个值,所以需要使用偏微分来分别计算
$$
\theta_0 := \theta_0 - \eta \frac {\partial E} {\partial \theta_0}
$$
$$
\theta_1 := \theta_1 - \eta \frac {\partial E} {\partial \theta_1}
$$
因为
$E$中没有直接的
$\theta$值,需要通过
$f_\theta(x)$进行展开计算,比较麻烦,此时可以使用复合函数的微分,令
$$
u=E(\theta)
$$
$$
v = f_\theta(x)
$$
那么
$E$ 对
$\theta_0$ 的微分可以表示为:
$$
\frac {\partial u} {\partial \theta_0} = \frac {\partial u} {\partial v} \cdot \frac {\partial v} {\partial \theta_0}
$$
先来计算
$\frac {\partial u} {\partial v}$
$$
\begin{align}
\frac {\partial u} {\partial v} &= \frac {\partial} {\partial v}E(\theta)\\
&= \frac {\partial} {\partial v} (\frac 1 2 \sum_{i=1}^n{(y^{(i)} - f_\theta(x^{(i)}))}^2)\\
&= \frac 1 2 \sum_{i=1}^n(\frac \partial {\partial v} (y^{(i)} - v)^2)\\
&= \frac 1 2 \sum_{i=1}^n(\frac \partial {\partial v} ({y^{(i)}}^2 - 2y^{(i)}v + v^2))\\
&= \frac 1 2 \sum_{i=1}^n(-2y^{(i)} + 2v)\\
&= \sum_{i=1}^n(v-y^{(i)})
\end{align}
$$
再来计算
$\frac {\partial v} {\partial \theta_0}$
$$
\begin{align}
\frac {\partial v} {\partial \theta_0} &= \frac {\partial} {\partial \theta_0} f_\theta(x)\\
&= \frac {\partial} {\partial \theta_0} (\theta_0 + \theta_1x)\\
&= 1
\end{align}
$$
最后结果
$$
\begin{align}
\frac {\partial u} {\partial \theta_0} &= \frac {\partial u} {\partial v} . \frac {\partial v} {\partial \theta_0}\\
&= \sum_{i=1}^n(v-y^{(i)}) \cdot 1\\
&= \sum_{i=1}^n(f_\theta(x^{(i)}) - y^{(i)})
\end{align}
$$
同样的方法,我们来计算一下对$\theta_1$进行微分的结果
$$
\frac {\partial u} {\partial \theta_1} = \frac {\partial u} {\partial v} \cdot \frac {\partial v} {\partial \theta_1}
$$
$\frac {\partial u} {\partial v}$之间已经计算过了,所以可以只计算
$\frac {\partial v} {\partial \theta_1}$
$$
\begin{align}
\frac {\partial v} {\partial \theta_1} &= \frac \partial {\partial \theta_1}(\theta_0 + \theta_1 x)\\
&= x
\end{align}
$$
结果为
$$
\begin{align}
\frac {\partial u} {\partial \theta_1} &= \frac {\partial u} {\partial v} \cdot \frac {\partial v} {\partial \theta_1}\\
&= \sum_{i=1}^n(v-y^{(i)}) \cdot x^{(i)}\\
&= \sum_{i=1}^n(f_\theta(x^{(i)}) - y^{(i)}) \cdot x^{(i)}\\
\end{align}
$$
此时之前的$\theta_0$和$\theta_1$两个表达式可以改为
$$
\begin{align}
\theta_0 &:= \theta_0 - \eta \sum_{i=1}^n(f_\theta(x^{(i)}) - y^{(i)}) & \\
\theta_1 &:= \theta_1 - \eta \sum_{i=1}^n(f_\theta(x^{(i)}) - y^{(i)}) \cdot x^{(i)} & \\
\end{align}
$$
此时可以设定初始学习率后不断开始学习计算,直到获取一个比较理想的结果
多项式回归
直线的拟合可以使用之前的最小二乘法,这次看一下曲线的拟合,定义如下的二次函数
$$
f_\theta(x) = \theta_0 + \theta_1x + \theta_2x^2
$$
对于$u$、$v$的值保持不变
$$
\frac {\partial u} {\partial \theta_2} = \frac {\partial u} {\partial v} \cdot \frac {\partial v} {\partial \theta_2}
$$
之前计算过的$\frac {\partial u} {\partial v}$的结果为$\sum_{i=1}^n(v-y^{(i)})$,这里需要对剩下的$\frac {\partial v} {\partial \theta_2}$进行计算
$$
\begin{align}
\frac {\partial v} {\partial \theta_2} &= \frac {\partial} {\partial \theta_2}(f_\theta(x))\\
&= \frac {\partial} {\partial \theta_2}(\theta_0 + \theta_1x + \theta_2x^2)\\
&= x^2
\end{align}
$$
最终
$\theta_2$的计算方式为
$$
\theta_2 := \theta_2 - \eta\sum_{i=1}^n(f_\theta(x^{(i)}) - y^{(i)})x^{(i)^2}
$$
多重回归
之前是只有一个变量的情况,当变量增多时,如下述公式
$$
f_\theta(x1, x2, x3) = \theta_0 + \theta_1x_1 + \theta_2x_2 + \theta_3x_3
$$
这种写法当
$x$有很多时,如
$x_1,x_2,x_3,x_4,x_5...x_n$写起来会很麻烦,这时候可以采用向量的表示方式
$$
\boldsymbol{\theta} =
\begin{bmatrix}
\theta_0 \\
\theta_1 \\
\theta_2 \\
...\\
\theta_n
\end{bmatrix}
$$
$$
\boldsymbol{x}=
\begin{bmatrix}
1 \\
x_1 \\
x_2 \\
...\\
x_n
\end{bmatrix}
$$
则表达式可以表示为
$\boldsymbol{\theta}$转置之后与
$\boldsymbol{x}$相等
$$
\begin{align}
\boldsymbol{\theta}^T\boldsymbol{x} &= \theta_0x_0+\theta_1x_1+\theta_2x_2+...+\theta_nx_n & \\
f_\boldsymbol{\theta}(\boldsymbol{x}) &= \boldsymbol{\theta}^T\boldsymbol{x} &\\
\end{align}
$$
保留之前设置的
$u=E(\theta)$及
$v=f_\theta(x)$,对于第
$j$个元素
$\theta_j$偏微分表达式为
$$
\frac {\partial u} {\partial \theta_j} = \frac {\partial u} {\partial v} \cdot \frac {\partial v} {\partial \theta_j}
$$
开始计算
$$
\begin{align}
\frac {\partial v} {\partial \theta_j} &= \frac \partial {\partial \theta_j}(f_\theta(x))\\
&= \frac \partial {\partial \theta_j}(\theta_0x_0+\theta_1x_1+... + \theta_jx_j + ... +\theta_nx_n)\\
&= x_j
\end{align}
$$
那么第
$j$个参数的更新表达式为
$$
\theta_j := \theta_j - \eta\sum_{i=1}^n(f_\theta(x^{(i)})-y^{(j)})x_j^{(i)}
$$
随机梯度下降法
最速下降法计算量大、计算时间长,同时容易陷入局部最优解(在某一个区间有一个最低点,但不是全局最低点,如果从这里附近开始,沿梯度下降方式寻找,可能只能找到这个局部最优解)
之前的公式中每次计算会把$i=1$到$n$期间的所有值都计算一遍,而在随机梯度下降法中,会随机选择一个训练数据,如选择一个 $k$
$$
\theta_j := \theta_j - \eta(f_\theta(x^{(k)})-y^{(k)})x_j^{(k)}
$$
我们也可以选择多个数据,来一起计算,也会减少一定的计算量,如选择
$m$个训练数据的索引集合为
$K$,这种做法被称为小批量梯度下降法
$$
\theta_j := \theta_j - \eta\sum_{k \in K}(f_\theta(x^{(k)})-y^{(k)})x_j^{(k)}
$$
Python实现
最小二乘法
测试数据准备
测试数据 click.csv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| x,y
235,591
216,539
148,413
35,310
85,308
204,519
49,325
25,332
173,498
191,498
134,392
99,334
117,385
112,387
162,425
272,659
159,400
159,427
59,319
198,522
|
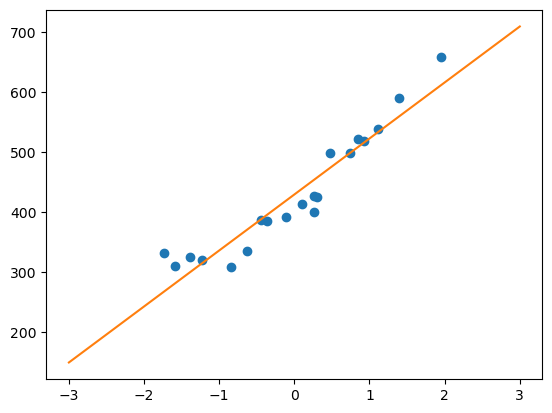
现在通过代码实现来拟合成一条直线
数据标准化(可选)
在正式处理之前,我们可以提前对数据进行一下标准化,这样可以让模型的收敛速度更快
标准化(标准差标准化或者叫Z-Score 标准化)的公式如下
$$
z^{(i)}=\frac {x^{(i)} - u} \sigma
$$
其中$u$是训练数据的平均值,$\sigma$是标准差,标准差的计算公式如下
$$
\sigma = \sqrt \frac {\sum_{(i=1)}^n(x_i - u)^2} {n}
$$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import numpy as np
import matplotlib.pyplot as plt
train = np.loadtxt('click.csv', delimiter=',', skiprows=1)
train_x = train[:,0]
train_y = train[:,1]
mu = train_x.mean()
sigma = train_x.std()
def standardize(x):
return (x - mu) / sigma
train_z = standardize(train_x)
|
这时候可以根据之前定义的$\theta_0$和$\theta_1$的更新表达式来进行计算,即
$$
\begin{align}
\theta_0 &:= \theta_0 - \eta \sum_{i=1}^n(f_\theta(x^{(i)}) - y^{(i)}) & \\
\theta_1 &:= \theta_1 - \eta \sum_{i=1}^n(f_\theta(x^{(i)}) - y^{(i)}) \cdot x^{(i)} & \\
\end{align}
$$
计算参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
theta0 = np.random.rand()
theta1 = np.random.rand()
def f(x):
return theta0 + theta1 * x
def E(x, y):
return 0.5 * np.sum(y - f(x) ** 2)
ETA = 1e-3
diff = 1
error = E(train_z, train_y)
while diff > 1e-2:
theta0 = theta0 - ETA * np.sum((f(train_z) - train_y))
theta1 = theta1 - ETA * np.sum((f(train_z) - train_y) * train_z)
current_error = E(train_z, train_y)
error, diff = current_error, error - current_error
x = np.linspace(-3, 3, 100)
plt.plot(train_z, train_y, 'o')
plt.plot(x, f(x))
plt.show()
|
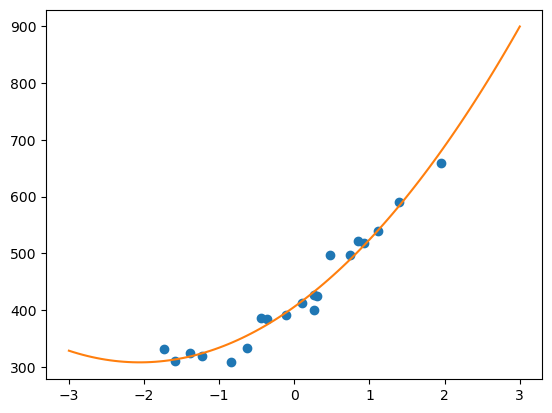
多项式回归实现
对应公式:$$f_\theta(x) = \theta_0 + \theta_1x+\theta_2x^2$$,这里考虑使用多重回归中用到的向量来进行简化计算
$$
\boldsymbol{\theta}=
\begin{bmatrix}
\theta_0 \\
\theta_1 \\
\theta_2 \\
\end{bmatrix}
$$
$$
\boldsymbol{x^{(i)}}=
\begin{bmatrix}
1 \\
x^{(i)} \\
{x^{(i)}}^2 \\
\end{bmatrix}
$$
对于训练数据$x$有很多,每一个都是一个矩阵
$
\boldsymbol{x^{(1)}}=
\begin{bmatrix}
1 \\
x^{(1)} \\
{x^{(1)}}^2 \\
\end{bmatrix}
$
,
$
\boldsymbol{x^{(2)}}=
\begin{bmatrix}
1 \\
x^{(2)} \\
{x^{(2)}}^2 \\
\end{bmatrix}
$
,
$
\boldsymbol{x^{(3)}}=
\begin{bmatrix}
1 \\
x^{(3)} \\
{x^{(3)}}^2 \\
\end{bmatrix}
$
,...
$
\boldsymbol{x^{(n)}}=
\begin{bmatrix}
1 \\
x^{(n)} \\
{x^{(n)}}^2 \\
\end{bmatrix}
$
我们要求解的训练数据结果就是这个矩阵,其中即是对于每一个值计算$f_\theta(x)$的结果
$$
\begin{bmatrix}
\theta_0 + \theta_1x^{(1)}+\theta_2{x^{(1)}}^2 \\
\theta_0 + \theta_1x^{(2)}+\theta_2{x^{(2)}}^2 \\
...\\
\theta_0 + \theta_1x^{(n)}+\theta_2{x^{(n)}}^2 \\
\end{bmatrix}
$$
可以转换为:
$$
\begin{bmatrix}
1 & x^{(1)} & {x^{(1)}}^2 \\
1 & x^{(2)} & {x^{(2)}}^2 \\
1 & x^{(3)} & {x^{(3)}}^2 \\
\vdots & \vdots & \vdots \\
1 & x^{(n)} & {x^{(n)}}^2 \\
\end{bmatrix}
\cdot
\begin{bmatrix}
\theta_0 \\
\theta_1 \\
\theta_2 \\
\end{bmatrix}
$$
再次进行转换
$$
\begin{bmatrix}
{\boldsymbol{x}^{(1)}}^T \\
{\boldsymbol{x}^{(2)}}^T \\
{\boldsymbol{x}^{(3)}}^T \\
\vdots \\
{\boldsymbol{x}^{(n)}}^T \\
\end{bmatrix}
\cdot \\
\begin{bmatrix}
\theta_0 \\
\theta_1 \\
\theta_2 \\
\end{bmatrix}
$$
这样可以编写出如下代码
1
2
3
4
5
6
7
8
9
10
11
|
theta = np.random.rand(3)
def to_matrix(x):
return np.vstack([np.ones(x.shape[0]), x, x**2]).T
X = to_matrix(train_z)
def f(x):
return np.dot(x, theta)
|
这时候我们再来看一下参数更新的表达式:$\theta_j := \theta_j - \eta\sum_{i=1}^n(f_\theta(x^{(i)})-y^{(j)})x_j^{(i)}$,考虑一下如何使用向量来简化计算,其中$\sum_{i=1}^n(f_\theta(x^{(i)})-y^{(j)})x_j^{(i)}$可以转换为,这样可以同时针对不同的$x$进行计算
$$
\begin{bmatrix}
f_\theta(x^{(1)})-y^{(1)} & f_\theta(x^{(2)})-y^{(2)} & ... & f_\theta(x^{(3)})-y^{(3)}
\end{bmatrix}
\cdot
\begin{bmatrix}
1 & x^{(1)} & {x^{(1)}}^2 \\
1 & x^{(2)} & {x^{(2)}}^2 \\
1 & x^{(3)} & {x^{(3)}}^2 \\
\vdots & \vdots & \vdots \\
1 & x^{(n)} & {x^{(n)}}^2 \\
\end{bmatrix}
$$
代码实现如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
diff = 1
ETA = 1e-3
def E(x, y):
return 0.5 * np.sum(y - f(x) ** 2)
error = E(X, train_y)
while diff > 1e-2:
theta = theta - ETA * np.dot(f(X) - train_y, X)
current_error = E(X, train_y)
diff, error = error - current_error, current_error
|
绘制一下拟合曲线
1
2
3
4
5
|
x = np.linspace(-3, 3, 100)
plt.plot(train_z, train_y, 'o')
plt.plot(x, f(to_matrix(x)))
plt.show()
|
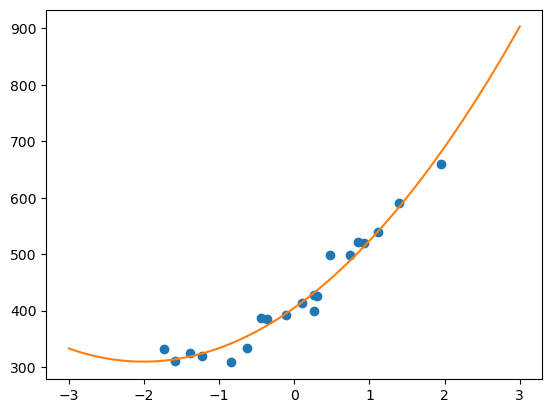
随机梯度下降法
随机梯度下降法对应公式为
$$
\theta_j := \theta_j - \eta(f_\theta(x^{(k)})-y^{(k)})x_j^{(k)}
$$
对应代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| theta = np.random.rand(3)
def MSE(x, y):
return (1 / x.shape[0]) * np.sum((y - f(x)) ** 2)
errors = []
diff = 1
errors.append(MSE(X, train_y))
while diff > 1e-2:
p = np.random.permutation(X.shape[0])
for x, y in zip(X[p, :], train_y[p]):
theta = theta - ETA * (f(x) - y) * x
errors.append(MSE(X, train_y))
diff = errors[-2] - errors[-1]
x = np.linspace(-3, 3, 100)
plt.plot(train_z, train_y, 'o')
plt.plot(x, f(to_matrix(x)))
plt.show()
|
总结
具体总的流程可以总结为
- 确定误差函数,需要找到当其结果最小时,其他参数的值
- 确定误差函数的偏/微分
- 确定梯度下降公式(可以简单理解为,先随机取一个值,然后向误差函数结果值偏小的方向去移动,重新计算,直至移动后,结果变化差值为0或基本无变化,可以认为达到了误差最小值)
- 使用梯度下降公式重复计算,直至获取结果